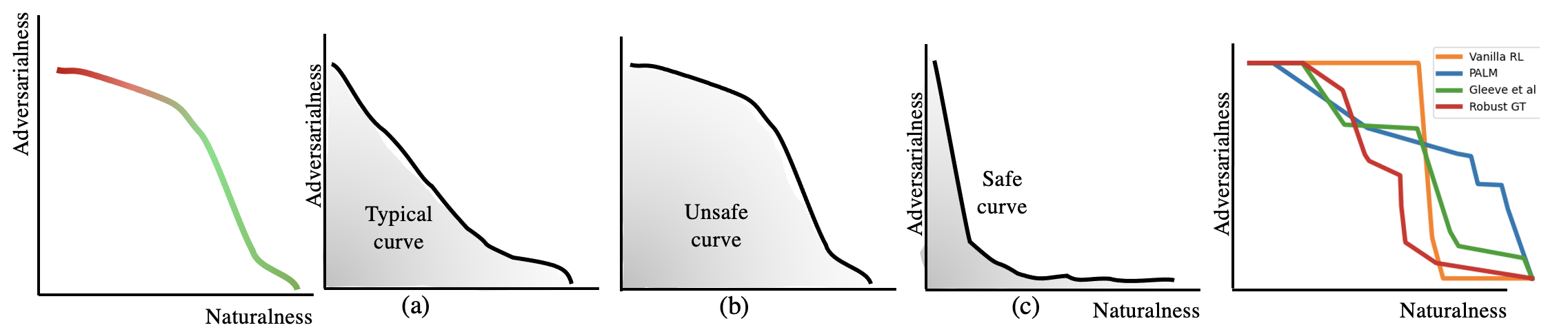
Motivations
Our ultimate goal is to build robust policies for robots that assist people. What makes this hard is that people can behave unexpectedly at test time, potentially interacting with the robot outside its training distribution and leading to failures. Let's consider assistive robots, the pinnacle of human-robot interaction. You trained an RL policy to assist someone with disability in an activity of daily living, i.e. the person has an itch on their arm and they can't scratch themselves. How would you know that this policy is safe to deploy?